
カラムに階層構造があるテーブルから、再帰SQLを実行したときにループの関係が存在すると、無限ループになってSQLがエラーになることがあります。
無限ループを回避するために、最大再帰数を指定する方法もありますが、実行されるSQLに過不足があるかもしれません。
この記事では最大再帰数を指定せずに、配列で概に取得したデータを管理して無限ループを回避する方法を解説します。
この記事ではPostgreSQLで説明しますが、書き方が少し異なるだけで他のDBMSでも同じことが実現できると思います。(無責任)
データ準備
解説のために上司と部下の関係が格納されているテーブルを用意します。
CREATE TABLE sup_sub(
supervisor varchar, --上司
subordonate varchar --部下
);
INSERT INTO sup_sub (supervisor, subordonate) VALUES
('empA', 'empF'),
('empF', 'empD'),
('empB', 'empC'),
('empF', 'empC'),
('empE', 'empB'),
('empD', 'empB'),
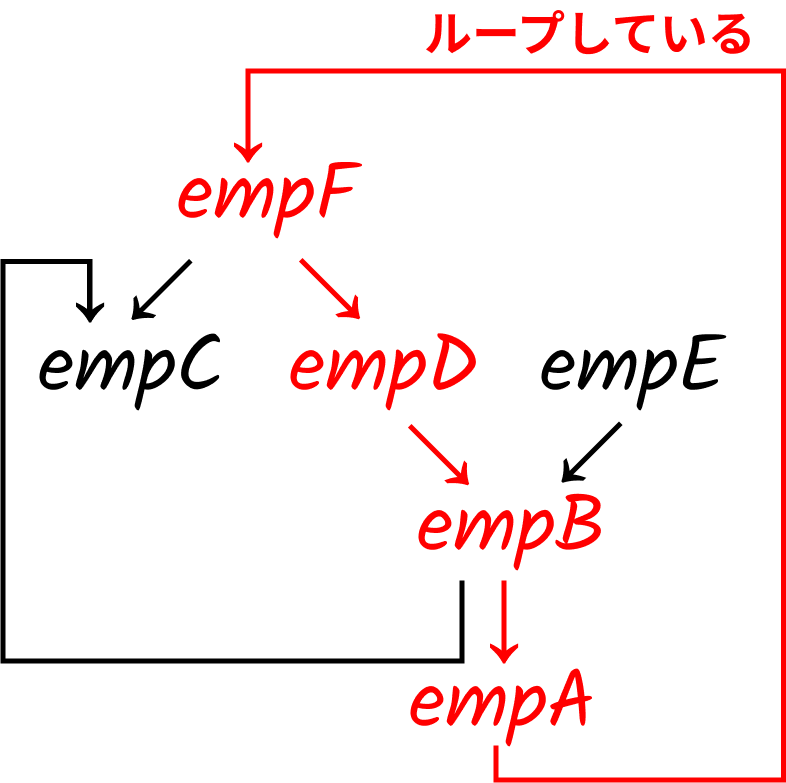
('empB', 'empA');可視化してみます。矢印の元が上司で、先が部下だとします。普通ではありえないと思いますが、再帰SQL実行時にループしたいので、部下が上司の上司の上司のような関係を作っています。

再帰SQLの簡単な説明
簡単に説明すると再帰SQLは以下の構成になっています。
WITH RECURSIVE ★ AS (
-- 非再帰項
SELECT ~ FROM 再帰SQL取得対象のテーブル
UNION ALL
-- 再帰項
SELECT ~ FROM ★
)
SELECT ~ FROM ★;1回目は非再帰項のSQLを実行してその結果に★という名前を付けます。2回目以降は再帰項のSQLが実行されます。再帰項の★はn-1回目のSQLの結果です。n回目実行時に、n-1回目のSQLの結果が空の場合に、再帰SQLが終了し1回目からn-1回目までの結果をUNION ALLしたものに★という名前が付けられます。最後に最下部のSQLでその★の結果から必要なデータを取得します。
こちらの記事でSQLの再帰について詳しく解説しています。
無限ループしてみる
先ほど作成したテーブルからempAの上司、の上司、の上司、…などすべての上司を取得してみます。
-- 再帰SQLで上司を取得
WITH RECURSIVE r AS (
-- 非再帰項
SELECT
supervisor
FROM sup_sub
WHERE subordonate = 'empA' -- 部下がempAの上司を取得
UNION ALL
-- 再帰項
SELECT
sup_sub.supervisor
FROM sup_sub
INNER JOIN r
ON sup_sub.subordonate = r.supervisor -- 前回の取得した結果の上司が部下であるデータ取得
)
SELECT * FROM r;このSQLを実行すると無限ループに陥るので、いくら待っても結果が返ってこなかったり、タイムアウトになったりします。
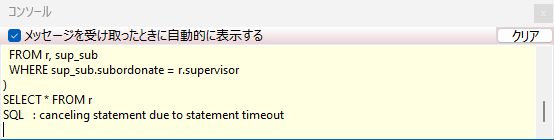
原因はempAの上司をたどっていくと、empB、empD、empF、empAとループをしているのでいつまでもSQLの実行が終わらないからです。
無限ループの回避
ここからが本題です。
無限ループを防ぐために、配列で既に見たデータを管理します。
今回の場合は既に見た上司をdata_pathという名前の配列に格納していき、まだ見ていない上司だけを取得していくことで無限ループしないようにしています。
配列に加えているのが、4行目と、13行目で、18行目で上司を取得済みかどうかを判定しています。
WITH RECURSIVE r AS (
SELECT
supervisor,
ARRAY[supervisor::text] as data_path, -- 取得済み上司を配列で管理
1 as exe_order
FROM sup_sub
WHERE subordonate = 'empA'
UNION ALL
SELECT
sup_sub.supervisor,
sup_sub.supervisor::text || data_path as data_path, -- 取得済み上司を配列で管理
exe_order + 1 as exe_order
FROM sup_sub
INNER JOIN r
ON sup_sub.subordonate = r.supervisor
WHERE not (sup_sub.supervisor = ANY(data_path)) -- 上司が取得済みかどうか判定
)
SELECT * FROM r where supervisor <> 'empA' order by exe_order;以下実行結果です。empAのすべての上司が取得できていますね。

まとめ
- 階層構造があるテーブルで再帰SQLを実行すると無限ループする可能性がある
- 配列で既に取得したデータを管理するとこで、無限ループを回避できる

